Data Disease Costing Superannuation Funds Millions
“If we had known THAT, we would have made a very different decision” – a data quality story I hear all too often when working in superannuation and wealth administration. Reliable, accurate and timely information is critical to the industry’s future. So too is minimising data errors which are costing the industry and its customers millions each year.

Poor data quality isn’t just a technical problem, it’s a customer service problem.
Poor data quality isn’t just a technical problem, it’s a compliance problem.
Poor data quality isn’t just a technical problem , it’s a financial problem.
In this article, I describe some of the key principles I have observed in my years embedded in the industry working through data quality issues with institutions large and small.
THE COST OF DATA ERRORS
Data errors are costly in so many respect…remediation expenditure, compensation payments, reputational damage just to name a few. Not only that, but the longer a data quality error goes undetected and unresolved, the greater the harm to bottom lines for institutions and members. The exponential harm which the proliferation of data errors can cause can aptly be characterised as the ‘disease effect’. If data quality issues are not detected and remedied soon after occurring, there is a tendency for the error to spread to contaminate or infect other data, jumping across to other systems if not quarantined and corrected.
Data quality issues are not just an IT or technology issue, there are all too real financial consequences. The financial harm of poor data typically follows a variation of the 1-10-100 rule. The traditional interpretation of the rule suggests that verifying the quality of a data record costs $1. Remediation by cleansing and de-duplicating a record costs $10. Working with a record that is of poor quality and inaccurate costs $100.
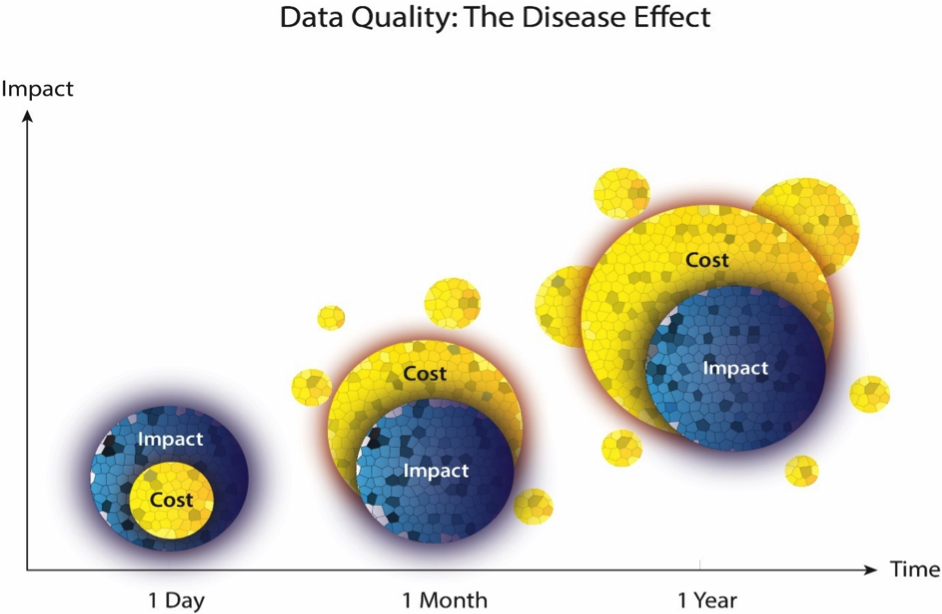
QMV’s experience suggests a 1-5-50 rule, whereby identifying the error after:
ONE DAY and the remediation cost is minimal. While the errant data requires correction, the error can be quarantined to minimise any external visibility and further impact.
ONE MONTH and there is a five-fold increase in the cost to remediate. The error may have filtered into several monthly processes (fees, premiums), some investors may have left or transferred products (super to pension), and the remedial costs begin to escalate.
ONE YEAR and there is a fifty-fold increase in the cost to remediate. The error will likely have filtered into several annual processes (member statements, ATO, APRA reporting); and may now be a breach which requires compensation and additional reporting to various external stakeholders.
The costs aren’t merely financial either. The damage that poor data quality can have on customer service and an organisations reputation is profound. There is nothing more likely to break the trust that Australians place in financial services institutions than ‘stuffing up’ their hard-earned savings.
The impact of poor data quality also extends to the compliance obligations of financial institutions, both generally and specifically. On one hand, poor data quality can cause a specific breach to laws, fund rules or policies which need to be complied with. Even worse, systemic data quality issues can lead to major breaches and regulatory intervention.
In terms of financial, reputational and non-compliance costs, it is clear that time makes things worse.
THE ‘GROUNDHOG DAY’ OF DATA ERRORS
At QMV, we sometimes refer to the data migration process as the ‘Groundhog Day’ of data quality errors. Just as Bill Murray’s Phil Connors perishes at the end of each day in the seminal 90’s cinematic classic, most migration processes follow a similar path.
The recurring mistake is the timing of the data quality effort. While data quality should always represent the first phase of a migration, it is too often left to the business to deal with as a ‘post migration’ activity. The blinkered focus on project deadlines often sees data quality efforts de-scoped, with identified data errors reclassified downward from ‘severity 1′ to ‘severity 2′ until they are overlooked.
Then, 18 months post migration, funds are cornered into a costly and painful major data remediation program … why? because during the migration, errors have been de-prioritised or ignored, people throw their hands up saying, “not my job” and the problem over time gets way out of hand.
THE PSYCHOLOGY OF DATA QUALITY SPENDING
How much do we spend on data quality? Well done to anyone who can confidently answer this question, because you are in the absolute minority. For everyone else, the answer is probably ‘more than you think and more than you need to’.
We can look at the spending in data quality through three classifications:
PREVENTION: controls designed to stop errors from happening;
DETECTION: controls to identify once a data quality error occurs; and
CORRECTION: remediation and restoration of data errors
For most executives, data quality is viewed as an expense rather than as an investment. This may seem like an innocuous play on words, but it is a very important distinction. Without understanding or measuring the return on investment that data quality can deliver, this leads to the reactive type approach whereby data quality spending it heavily geared toward correction.
The key is to break the endless cycle of manually fixing defective data, by transitioning from a reactive approach heavily focused on correction to one that finds the appropriate balance between all three classifications. In addition, corrective controls are more targeted, helping to mitigate the spread of the ‘disease effect’.
HOW TO IMPROVE DATA QUALITY
So then, what can be done to improve data quality, and reduce data quality related risks? There are a few key initiatives that can help to eliminate the ‘disease effect':
1. Develop a series of data quality metrics: put simply, you cannot manage what you do not measure. A metrics-based approach will provide a factual basis on which to justify, focus and monitor efforts while acting as a leading risk indicator.
2. Determine ownership: like all strategic initiatives, data quality will not succeed without the oversight, collaboration and accountability of all key stakeholders.
3. Invest in a data quality system: helping to break to cycle of word documents, spreadsheets and SQL scripts, an integrated data quality system can help drive the real cost efficiencies and risk management that true data quality can deliver.
4. Measure return on investment (ROI): the key to measuring ROI is about choosing the metrics that matter most to the business – those that can be measured and offer the biggest potential for improvement.
Addressing the points above should help transition from a reactive approach heavily focused on correction to one that finds the appropriate balance between prevention, detection and correction controls. This will lead to more of the $1 verifications and less of the $100 corrections.
Of course, each error is different and there is no one-size- fits-all approach for measuring the associated cost. Whether it’s 1-10-100 or 1-3-10 or 1-50-1000, the key theme is clear: the financial and reputational costs of data errors spread like a disease. While prevention is better than cure and remains the optimum solution, early detection is a critical tool that can significantly reduce the cost and impact of data errors.
Regards
Mark
Mark Vaughan – Co-founder
If your fund has a data issue or would like to get more from data, then please contact QMV for a preliminary discussion. You might be interested in checking out QMV’s purpose built superannuation member profiling and data quality management software Investigate.